You are here
Why We Developed DBStream
Tue, 05/19/2015 - 17:10 — Arian Bär (Fors...

TL;DR
Systems for processing network monitoring data need to offer high performance and usability. We think the Open Source system DBStream offers both.
/TL;DR
When I started working at FTW, my main task was to speed up data processing. This was not an easy task, especially since nothing should be sacrificed.
All data should be stored, access should be instantaneous, answers should be exact and the implementation and deployment of typical processing tasks should be easy.
So we looked at multiple tools which where commonly used to solve those challenges. First, we looked at Hadoop, which back then was in a rather early stage, providing not that great performance and for using it people would need to implement Java programs (which was a problem since our team is coming from a C background).
Then we looked at complex index structures like bitmap indices which make file access faster. Here, the main problem was that we would still need to use and handle files, which has all the drawbacks like complex directory structures, concurrent access and many more. In addition, the tools we tried had some problems and did not seem to be production ready. The last thing we look at where database systems. They offered the high level, declarative query language SQL, indexing functionality and are made for storing and handling data.
But, they have the following problems:
- Importing data is slow (especially single row INSERTs).
- As tables get bigger, performance suffers (especially index structures become slow to maintain).
- Parallelization is not supported out of the box.
Therefore, we started looking into ways how to solve those performance issues. We were able to solve the import problem by using a dedicated COPY command offered by PostgreSQL. But, the second and third problem still remained. Therefore, we investigated the structure of our data more closely, in order to find a solution for our problem.
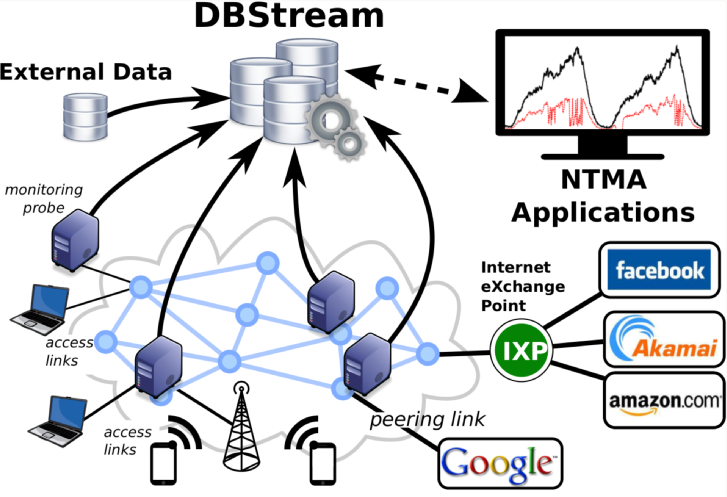
Network monitoring data has properties typically found in sensor data. All recorded data is about events which happened in the past.
Those events do not change after they have been monitored. In addition, only new events are added to the end of the stream. Thus, the stream continues to grow and can get very big if recorded over extended time periods.
After evaluating several different approaches, we found that partitioning the data based in the time stamp solves all the mentioned problems. First, for each, e.g., 10 minutes, we create a new table partition. Such a partition does not get that big anymore and therefore indices can be created once and do not have to be updated and deleting old data can be done by just deleting the oldest partitions. In addition, queries can now be executed on multiple partition in parallel, which can be used to speed up processing. Therefore, we decided to use a regular Postgresql database as the data processing and storage engine for DBStream.
What can I do with DBStream?
In the first version of the system, data were imported automatically from a monitoring probe into the database. On the imported data, people could run simple queries, apply deep statistics, export the results for plotting and many other tasks. The problem was that whenever people wanted to access data they had to go back to the imported data, which in fact was very big (e.g. up to 1 TB a day, for some streams). Obviously, an aggregation of several days or weeks of data of this size either takes some time or costs a lot of resources (buying and maintaining more disks). In addition, it is very expensive to store extended amounts of time of data of this size. On the other hand many of the performed analysis actually needed only a small part of the imported data and typically at higher granularities (if you want to plot two weeks of data it does not make sense to use a per (milli-)second aggregation).
To solve this problem, we started to filter and pre-aggregate the data and only store the aggregation results over extended time periods. But if you want to apply this approach manually it is a very cumbersome task, where, e.g., every day someone has to run the aggregation. The next automation step is use Cron jobs to start the aggregation automatically for you. So that is what we implemented and for some tasks it worked fine.
But after some time and multiple implemented aggregations, we realized that this approach is not optimal. Since data is imported in batches, the aggregation can only start after a full batch as finished. Therefore, if we import data in 1 hour batches when should we start the daily aggregation?
If we start it at 0:00 the last hour of data of the previous day, from 23:00:00 to 23:59:59 will not have finished importing since it could only start importing at 23:59:59. Therefore, we somehow need to guess how long it takes to process this hour and then start the aggregation. Now, if there is, e.g., an anomaly causing more data than normal to be produced, the import will take longer and we should start the aggregation later. That means, before starting the aggregation we should actually check if the data is really available and only then start the aggregation.
For just a couple of aggregations this is doable, but problems get more serious when you want to run many aggregations and especially if you want to run aggregations on top of other aggregations. In addition, running the aggregation of a whole day consumes quite some resources, especially if multiple such aggregations are running at the same time. Also monitoring and operating those aggregations gets a mess since there is no single point to get any information about which aggregations are running, which had a problem or failed and what was the reason for failing. You have to look in the log of the Cron job, the PostgreSQL log and in your case in the log output of the stored procedures we wrote to handle processing the aggregations. If a aggregation needs data from two import streams the synchronization becomes really cumbersome.
Those problems led us to design and implement the DBStream system. In DBStream, in addition to the monitoring results, each row has a time stamp.
This time stamp is then used by DBStream to not only partition the data, but also to automatically start any aggregations registered on top of the imported data. Of course, the output of a aggregation can be used as the input to another aggregation and each aggregation can have multiple input streams.
In DBStream the time windows can be set much smaller than a full day. Therefore, imported data are aggregated as they arrive at the system and not only once in the night.
A typical DBStream aggregation job looks like this:
<job inputs="A (window 60min)" output="B" schema="serial_time int4, total_download int8, total_upload int8">
<query>
select _STARTTS, sum(download), sum(upload) from A group by _STARTTS
</query>
</job>
The DBStream SCHEDULER module automatically starts aggregations as soon as enough data has arrived in all input windows of a job. The query specified by the user can use the full SQL syntax offered by PostgreSQL, including also user defined functions.

Performance comparison of DBStream vs. Spark, for details about the executed workload and used datasets please refer to [2].
If this article made you interested in DBStream we recommend you to have a look at the Github page: https://github.com/arbaer/dbstream/ and would like to point you to our most recent publications:
In [1], we give an overview of the different applications we implemented using DBStream and in [2] we presents a performance comparison of DBStream with Apache Spark.
Arian Baer (arian.baer _at_ gmail.com)
[1] Arian Baer, Pedro Casas, Lukasz Golab and Alessandro Finamore "DBStream: An Online Aggregation, Filtering and Processing System for Network Traffic Monitoring", Wireless Communications and Mobile Computing Conference (IWCMC), 2014.
[2] Arian Baer, Alessandro Finamore, Pedro Casas, Lukasz Golab, Marco Mellia "Large-Scale Network Traffic Monitoring with DBStream, a System for Rolling Big Data Analysis", IEEE International Conference on Big Data (IEEE BigData), 2014.
|
The information available on this website is property of the contributing authors from the mPlane Consortium (project FP7-ICT-318627) and does not necessarily reflect the view of the European Commission. The information in this website is provided "as is", and no guarantee or warranty is given that the information is fit for any particular purpose. The user uses the information at its sole risk and liability. |