- ABOUT MPLANE
- NEWS
- Blogs
- EXTERNAL ADVISORY BOARD
- PUBLIC DELIVERABLES
- PUBLICATIONS
- TALKS
- STANDARDIZATION
- CALENDAR & EVENTS
- CONTACTS
- mPlane Industrial Workshop
- 1st PhD school on BigData
- EuCNC 2015 Exhibition
- Open Datasets
- SOFTWARE
- Demonstration guidelines
- Use cases
- Content Popularity Estimation
- Anomaly detection and root cause analysis
- Passive Content Promotion and Curation
- Active measurements for multimedia content delivery
- Quality of Experience for web browsing
- Mobile network performance issue cause analysis
- Verification and certification of service-level agreements
- mPlane Final Workshop
You are here
Content Popularity Estimation
General description
The goal of this use case is to optimize the QoE of the user and the network load by inferring the expected-to-be popular contents and identifying optimal objects to cache in a given portion of the network. To achieve this goal, we exploit the mPlane architecture in order to collect a large number of online traffic information requested by the users in several points in the network. The acquired information is exploited in order to predict the content popularity and suggest efficient caching replacement strategies to the Reasoner.
An overview of the use case is shown in the Figure below.
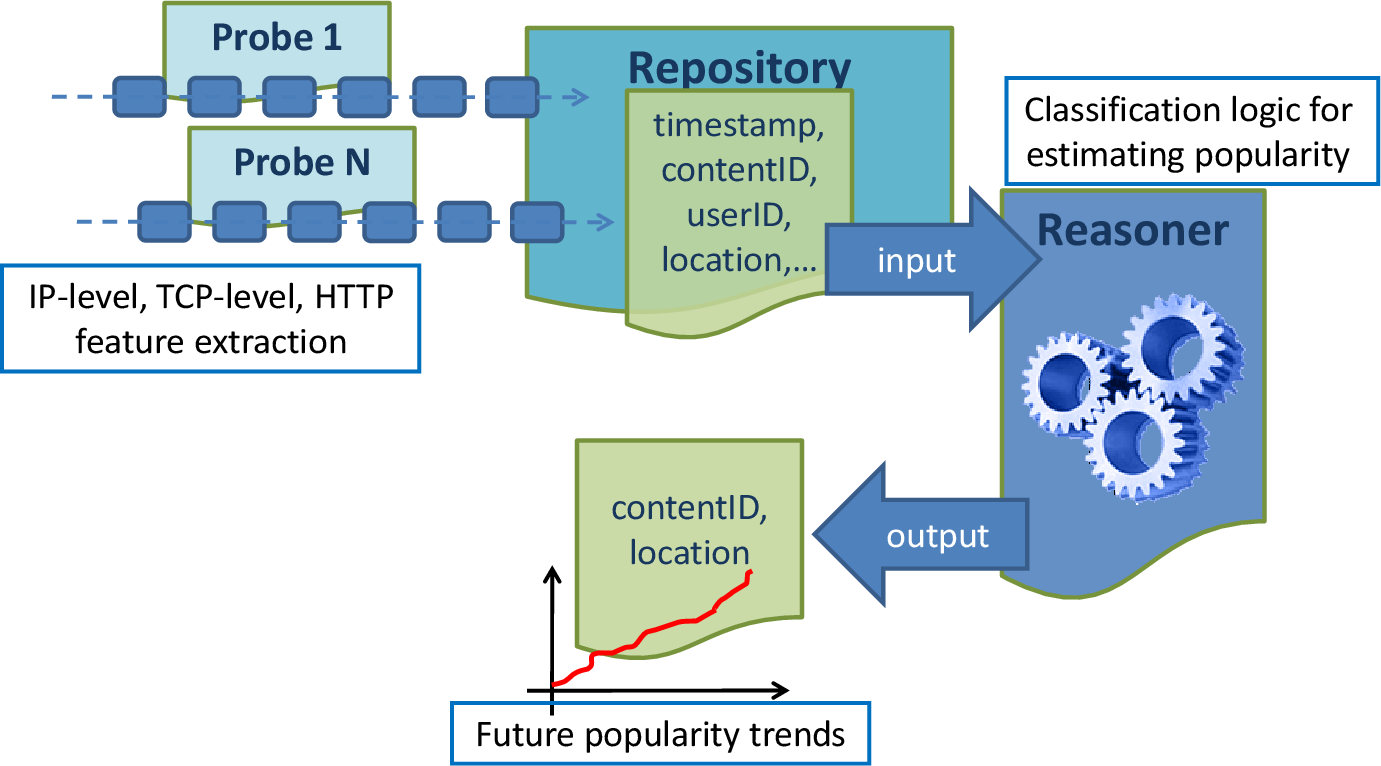
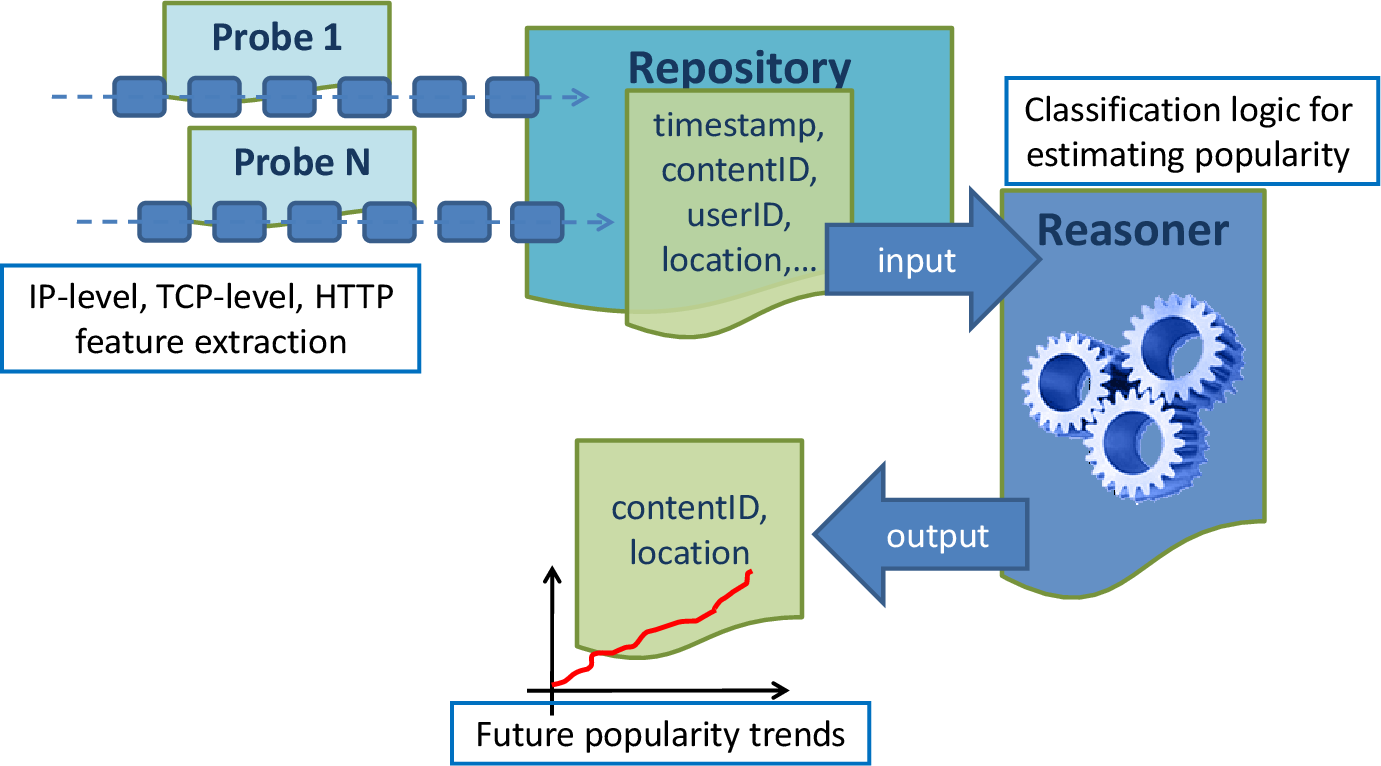
Components describing the architecture, and point to pieces of software
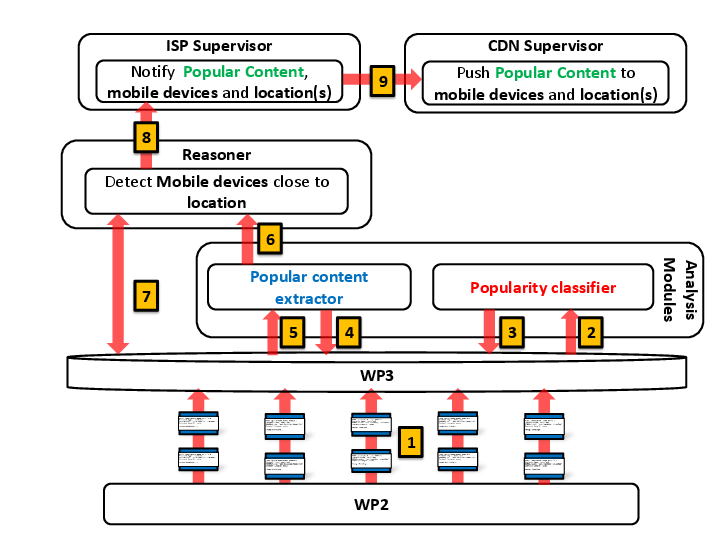
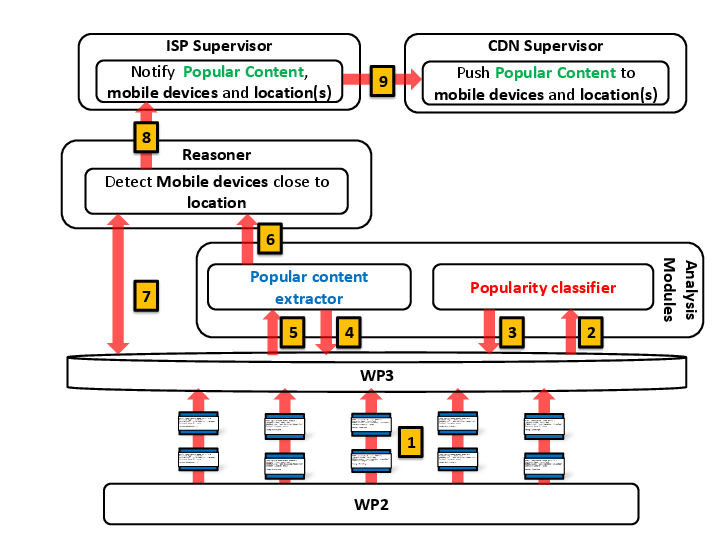
Figure below outlines the role of each mPlane's component, and more specifically, the WP4 analysis modules and their interactions with the repository and the Reasoner.
At first, probes located in different points of the network continuously collect information about the requests of the users, and stream requests to the central repository. For each request we store the associated timestamp and the network location of the
probe (Step 1). Based on these features, the analysis modules are responsible for predicting the future popularity of each requested contents at each part of the network (i.e., the probe location). This task is accomplished by employing two different
modules: the first one, named Popularity Classifier, takes as input the popularity history for a content (Step 2), it generates a signature for its request arrival process using the Heterogeneous Mixture Modelling technique, and classify such content in a Hierarchical Clustering Structure, that is stored at the repository (Step 3). In parallel, the Online Predictor, for each observed content explores the Hierarchical Clustering Structure (Step 4) to find the popularity pattern which maximizes a likelihood function (Step 5). Once the popularity pattern has been found, we use it to predict its future popularity. Thus, if the number of future views overcomes a static threshold N, an event is triggered to the Reasoner (Step 6) to notify which contents are becoming popular and where they are. Then, the Reasoner may query the repository to obtain the IDs of mobile devices, base stations and caches that are located within the same area of the probe, and may be interested at prefetching popular contents (Step 7). Then, for each popular content, its ID, together with the location of the probe and, possibly, a list of devices are forwarded to the supervisor of the ISP (Step 8). The ISP supervisor will exchange such information with other supervisors, e.g.,the supervisor of a CDN, to let it know which contents may be worthful to proactively push to its caches (Step 9).
How to setup and deploy the use-case
For the detailed instructions on the deployment, setup, and demo of the use-case we refer interested readers to the corresponding demontration guidelines page (link).
HOWTO setup and run it
Here follows the instructions to deploy and run the use case Content Popularity Estimation.
The code for the mPlane protocol Reference Implementation (RI) is available on GitHub under mPlane protocol RI.
Here we assume that [PROTOCOL_RI_DIR] is the folder where the GitHub repository of the mPlane protocol reference implementation has been cloned.
The code for the use case is available on GitHub under mPlane demo material.
Reasoner
cachereasoner is the Python script for the reasoner. It periodically runs the request which returns the list of contents to cache in a given server.
Supervisor
The Python code for the supervisor is the one provided in the mPlane protocol RI repository, i.e., scripts/mpsup. It receives the requests from the reasoner and forwards them to the repository and analysis module component.
Repository and Analysis Module
cacheController.py is the Python script that returns the list of contents to cache. tstatrepository.py integrates the script above with the capabilities of communicating with Tstat.
Tests done considering integration, performance, validation tests
The testing of each component (being it probe, repository, supervisor or reasoner) and how it communicates with the remaining architecture is ongoing.
Links to all software used
- mPlane protocol RI: https://github.com/fp7mplane/protocol-ri
- mPlane components: https://github.com/fp7mplane/components
- Content Popularity Components: https://github.com/fp7mplane/demo-infra




{kind=link}
{kind=link}
|
The information available on this website is property of the contributing authors from the mPlane Consortium (project FP7-ICT-318627) and does not necessarily reflect the view of the European Commission. The information in this website is provided "as is", and no guarantee or warranty is given that the information is fit for any particular purpose. The user uses the information at its sole risk and liability. |