- ABOUT MPLANE
- NEWS
- Blogs
- EXTERNAL ADVISORY BOARD
- PUBLIC DELIVERABLES
- PUBLICATIONS
- TALKS
- STANDARDIZATION
- CALENDAR & EVENTS
- CONTACTS
- mPlane Industrial Workshop
- 1st PhD school on BigData
- EuCNC 2015 Exhibition
- Open Datasets
- SOFTWARE
- Demonstration guidelines
- Estimating content and service popularity for network optimization
- Passive Content Promotion and Curation
- Active measurements for multimedia content delivery
- Quality of Experience for web browsing
- Mobile network performance issue cause analysis
- Anomaly detection and root cause analysis in large-scale networks
- Verification and Certification of Service Level Agreement
- Use cases
- mPlane Final Workshop
You are here
Guidelines for Estimating content and service popularity for network optimization
Requirements
This page details the requirements that are specific to the Contet Popularity Estimation use case, in addition to those expressed for the Reference demonstration environment (link).
Hardware list
- Probe: One dedicated machine running Tstat as passive traffic probe
- Repository: One dedicated machine for the repository running MongoDB and the analysis modules for the Content Popularity Estimation.
Software list
- mPlane framework for the use-case (GitHub repository)
Probes
- Tstat - Passive network traffic collection and analysis (mPlane page, GitHub repository)
Repositories
- MongoDB - a cross platform, open-source document database (official page).
Reasoner
- Reasoner for the Content Popularity Estimation (mPlane page)
Software dependencies
- Probe: Linux OS and Python3
- Repository: Linux OS, Python3 and MongoDB 3.0 or higher
Software installation
- Download and install Tstat; follow the instructions at GitHub repository
- Download and install MongoDB; follow the instructions at its official page
- Download and install the Tstat mPlane proxy interface; follow the instructions at GitHub repository
- Download and install the mPlane proxy for the repository, tstatrepository.py (customised for this specific use-case) and the reasoner, cachereasoner, from the GitHub repository for this demo.
Run the software
- Run Tstat (check the mPlane page for details):
sudo ./tstat/tstat -l -i DEVNAME -s OUTPUTDIR
- Run MongoDB (check its official page for details):
sudo /etc/init.d/mongodb start
Run the mPlane software
Here we assume that [PROTOCOL_RI_DIR] is the folder where the GitHub repository of the mPlane protocol reference implementation has been cloned.
The code for the use case is available on GitHub under mPlane demo material.
Reasoner
cachereasoner is the Python script for the reasoner. It periodically runs the request which returns the list of contents to cache in a given server.
Supervisor
The Python code for the supervisor is the one provided in the mPlane protocol RI repository, i.e., scripts/mpsup. It receives the specification from the reasoner and forwards them to the repository and analysis module component.
Repository and Analysis Module
tstatrepository.py integrates the capabilities of communicating with Tstat and the interface to query the analysis module.
HowTo
1. Set the parameters in the files supervisor.conf, tstatrepository.conf, reasoner.conf (e.g., path to certificates, supervisor address, client port and address, and roles)
2. Set the following parameters in the files cacheController.py and tstatrepository.py to connect to the Analysis module that estimates the content popularity of contents
_controller_address = Content Estimation analysis module address
_controller_port = Content Estimation analysis module port
3. Set the envirnoment variable MPLANE_RI to point to [PROTOCOL_RI_DIR]
$ export MPLANE_RI=[PROTOCOL_RI_DIR]
4. Run the mPlane components:
- Supervisor
$ ./scripts/mpsup --config ./conf/supervisor.conf
- Tstat proxy:
$ ./scripts/mpcom --config ./mplane/components/tstat/conf/tstat.conf
- Run the Repository proxy:
$ ./scripts/mpcom --config ./mplane/components/tstat/conf/tstatrepository.conf
- Run the reasoner (make sure you have set the MPLANE_RI variable)
$ python3 cachereasoner --config reasoner.conf
Step-by-step walkthrough
Warmup: activating the DB collection of content request timeseries
Once started, the mPlane proxy interface for Tstat should start exporting data (HTTP logs) to the repository interface. This will filter the HTTP requests based on a targeted kind of content (e.g., YouTube videos). Filtered content will be used to build request timeseries and which will be stored in the MongoDB database.
Observe: the content expected to be popular in the future and the accuracy of the prediction
The reasoner will periodically query the analysis modules to obtain the list of pieces of content which represent the best candidates to be cached in a CDN system based on their expected popularity.
This use-case shall run for a long period of time, and the demo will mainly demonstrate the feasibility of the approach and its viability using the mPlane protocol. For the sake of showcasing, the accuracy of the content popularity estimation environment will rely on the analysis of historical data we have collected in the past and pre-imported in the use-case repository (see plot below).
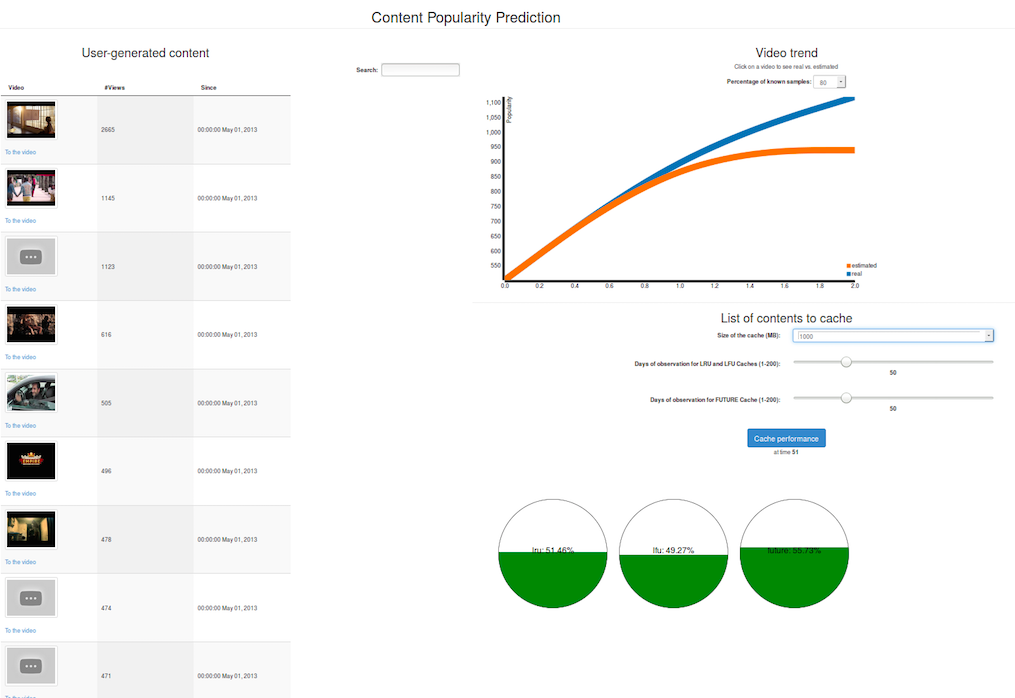

{kind=link}
|
The information available on this website is property of the contributing authors from the mPlane Consortium (project FP7-ICT-318627) and does not necessarily reflect the view of the European Commission. The information in this website is provided "as is", and no guarantee or warranty is given that the information is fit for any particular purpose. The user uses the information at its sole risk and liability. |