- ABOUT MPLANE
- NEWS
- Blogs
- EXTERNAL ADVISORY BOARD
- PUBLIC DELIVERABLES
- PUBLICATIONS
- TALKS
- STANDARDIZATION
- CALENDAR & EVENTS
- CONTACTS
- mPlane Industrial Workshop
- 1st PhD school on BigData
- EuCNC 2015 Exhibition
- Open Datasets
- SOFTWARE
- Demonstration guidelines
- Estimating content and service popularity for network optimization
- Passive Content Promotion and Curation
- Active measurements for multimedia content delivery
- Quality of Experience for web browsing
- Mobile network performance issue cause analysis
- Anomaly detection and root cause analysis in large-scale networks
- Verification and Certification of Service Level Agreement
- Use cases
- mPlane Final Workshop
You are here
Guidelines for Passive Content Promotion and Curation
Requirements
This page details the requirements that are specific to the Passive Content Curation in addition to those expressed for the Reference demonstration environment (link).
Hardware list
- Probe: One dedicated machine running Tstat as passive traffic probe
- Repository: One dedicated machine for the repository importer, the analysis modules for the Passive Content Curation, and the website used to present the captured URLs.
Software list
- mPlane protocol reference implementation (GitHub repository)
- mPlane framework for the use-case (GitHub repository)
Probe
- Tstat - Passive network traffic collection and analysis (mPlane page, GitHub repository)
Repository and analysis modules
- WeBrowse - an online HTTP request processing module which extracts URLs clicked by users (GitHub repository)
Reasoner
- Reasoner for the Passive Content Curation (mPlane page)
Software dependencies
- Probe: Linux OS and Python3
- Repository: Linux OS, Python3, pymysql and schedule Python modules
Supplemental software dependencies
This software is needed for to enable the presentation module (a website) for the URLs captured by WeBrowse:
- Apache 2.4.7 or higher (possibly configured in "worker" mode, which requires fast-cgi and php5-fpm packages)
- MySQL 14.14 or higher
- PHP 5.5.9 or higher
- Urllib2 for Python3
Software installation
- Download and install Tstat; follow the instructions at GitHub repository
- Download and install the mPlane proxy for the repository, tstatrepository.py (customised for this specific use-case), and the reasoner, reasoner, from the GitHub repository for this demo
Run the software
- Run Tstat (check the mPlane page for details):
sudo ./tstat/tstat -l -i DEVNAME -s OUTPUTDIR
Run the mPlane software
Here we assume that [PROTOCOL_RI_DIR] is the folder where the GitHub repository of the mPlane protocol reference implementation has been cloned.
The code for the use case is available on GitHub under mPlane demo material.
Supervisor
The Python code for the supervisor is the one provided in the mPlane protocol RI repository, i.e., scripts/mpsup. It receives the specification from the reasoner and forwards them to the other mPlane components.
Repository and Analysis Module
tstatrepository.py integrates the capabilities of communicating with Tstat and the interface to the query the analysis module.
Reasoner
reasoner is the Python script for the reasoner. It starts the Passive Content Curation demo by activating the streaming exporter of HTTP logs generated by Tstat, and periodically queries the tstatrepository to obtain the list of the most popular content observed in a given period.
HowTo
1. Set the parameters in the files supervisor.conf, tstatrepository.conf, reasoner.conf (e.g., path to certificates, supervisor address, client port and address, and roles)
2. Set the environment variable MPLANE_RI to point to [PROTOCOL_RI_DIR]
$ export MPLANE_RI=[PROTOCOL_RI_DIR]
3. Run the mPlane components:
- Supervisor
$ ./scripts/mpsup --config ./conf/supervisor.conf
- Tstat proxy:
$ ./scripts/mpcom --config ./mplane/components/tstat/conf/tstat.conf
- Run the Repository proxy:
$ ./scripts/mpcom --config ./mplane/components/tstat/conf/tstatrepository.conf
- Run the reasoner (make sure you have set the MPLANE_RI variable)
$ python3 reasoner --config reasoner.conf
Step-by-step walkthrough
Warmup: online extraction of user clicks from network traffic
Once started, the mPlane proxy interface for Tstat should start exporting data (HTTP logs) to the repository interface. This will filter the HTTP requests to extract those corresponding to actual clicks generated by users. The analsyis modules built on top of the streaming importer will also classify the URLs depending on the kind of content the point to (e.g., videos or news).
Observe: URLs observed in the network presented in a WeBrowse
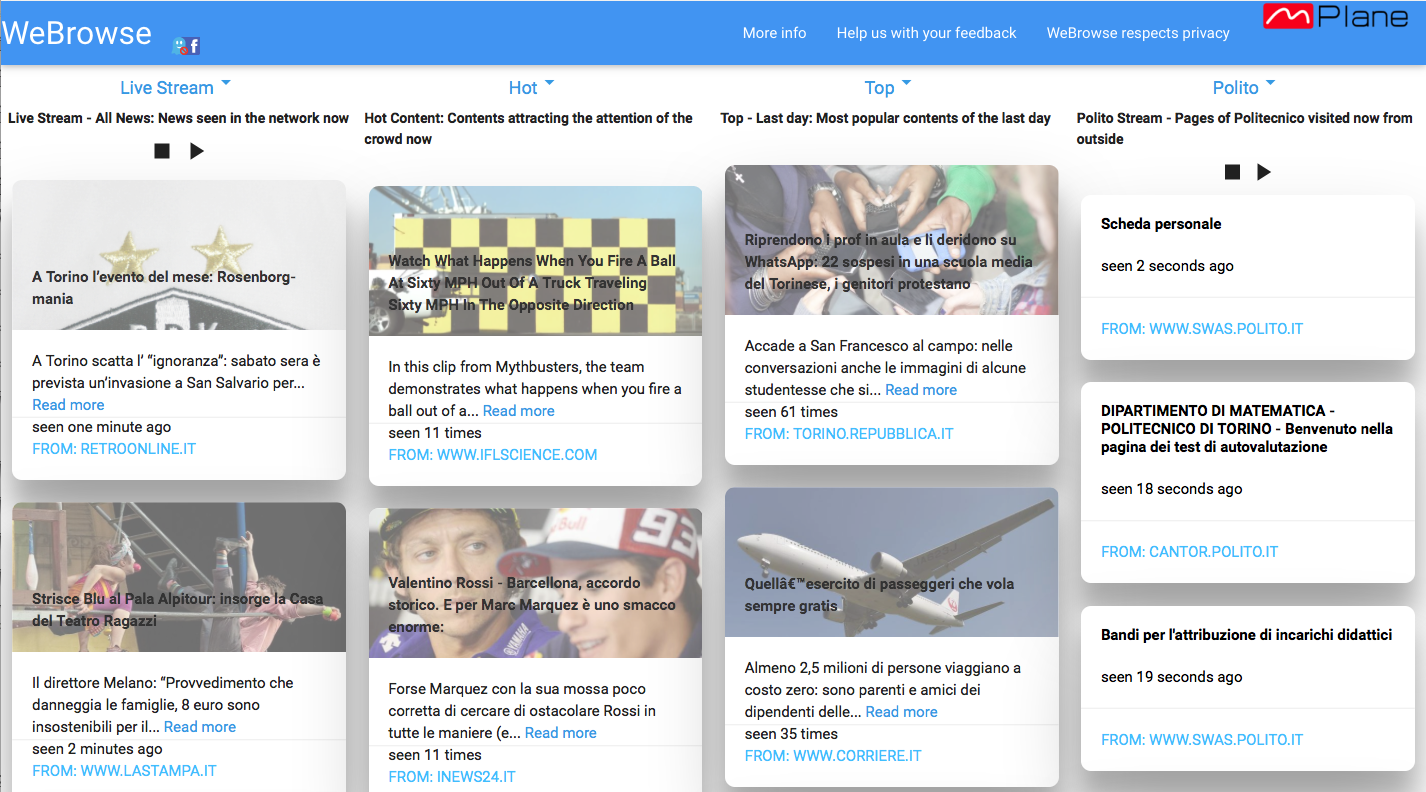
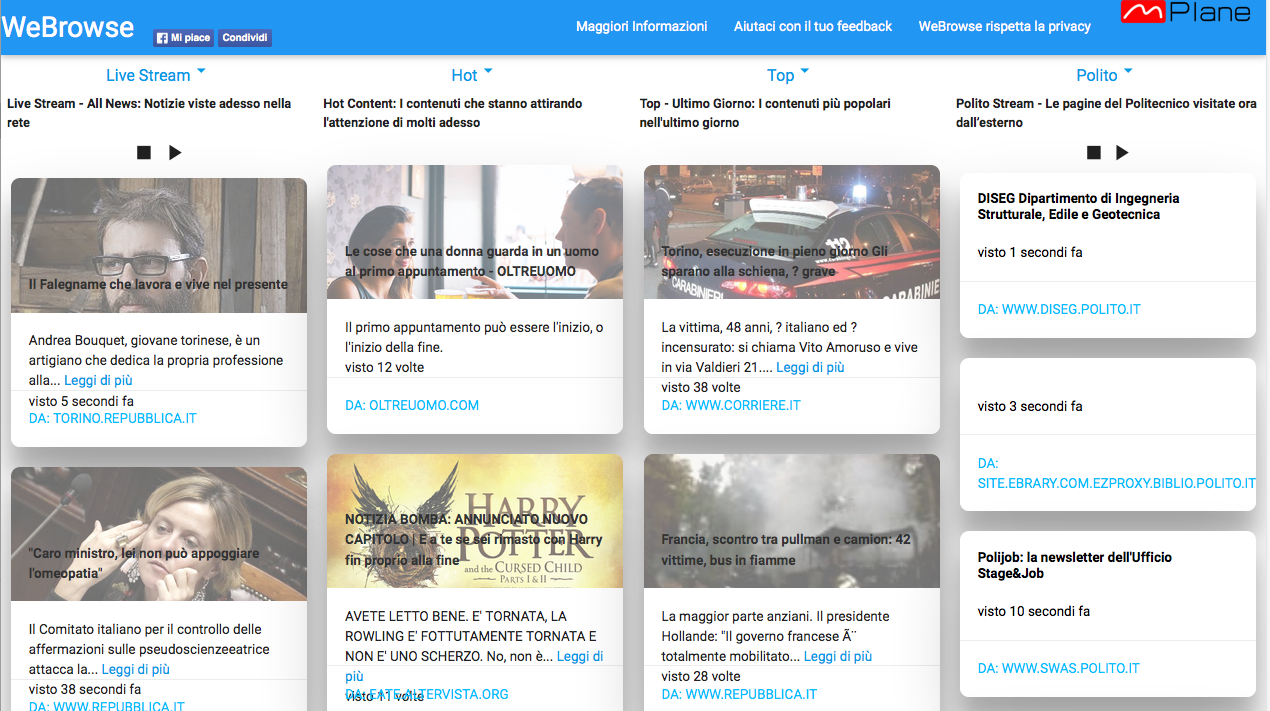
The demo will demonstrate the feasibility of the passive content curation approach and its viability using the mPlane protocol. For the sake of showcasing, the URLs extracted by the WeBrowse modules will be presented in a website, similar to the one available in Polito deployment, http://webrowse.polito.it (see the picture below). Notice that popular content exhibit as expected a strong locality bias, with italian newspages (having no english version) consistently showing up in the interface.
Trigger: visit webpages to have them presented in WeBrowse
During the demo we will emulate the behaviour of a user in the network by generating automatic visits to a list of news webpages. These will hence appear in the front-page of WeBrowse.




{kind=link}
|
The information available on this website is property of the contributing authors from the mPlane Consortium (project FP7-ICT-318627) and does not necessarily reflect the view of the European Commission. The information in this website is provided "as is", and no guarantee or warranty is given that the information is fit for any particular purpose. The user uses the information at its sole risk and liability. |