You are here
DBStream, a flexible and easy to use Data Stream Warehouse
![]()
Description
DBStream is a flexible, scalable and easy to use Data Stream Warehouse (DSW) designed and implemented at FTW. The main purpose of DBStream is to store and analyze large amounts of network monitoring data. Indeed, DBStream is tailored to tackled the requirements of Network Traffic Monitoring and Analysis (NTMA) applications, both in terms of storage and near real time data processing and analysis. DBStream is a repository system capable of ingesting data streams coming from a wide variety of sources (e.g., passive network traffic data, active measurements, router logs and alerts, etc.) and performing complex continuous analysis, aggregation and filtering jobs on them. DBStream can store tens of terabytes of heterogeneous data, and allows both real-time queries on recent data as well as deep analysis of historical data.
DBStream is implemented as a middle-ware layer on top of PostgreSQL. Whereas all data processing is done in PostgreSQL, DBStream offers the ability to receive, store and process multiple data streams in parallel. As we have shown in a recently published benchmark study [2], DBStream is at least on par with recent large-scale data processing frameworks such as Hadoop and Spark.
One of the main assets of DBStream is the flexibility it provides to rapidly implement new NTMA applications, through the usage of a novel stream processing language tailored to continuous network analytics. Called CEL (Continuous Execution Language), this declarative, SQL-based language is highly precise yet very easy to use. Using CEL, advanced analytics can be programmed to run in parallel and continuously over time, using just a few lines of code.
The near real time data analysis is performed through the online processing of time-length configurable batches of data (e.g., batches of one minute of passive traffic measurements), which are then combined with historical collections to keep a persistent collection of the output. Moreover, the processed data can then be easily integrated into visualization tools (e.g., web portals).
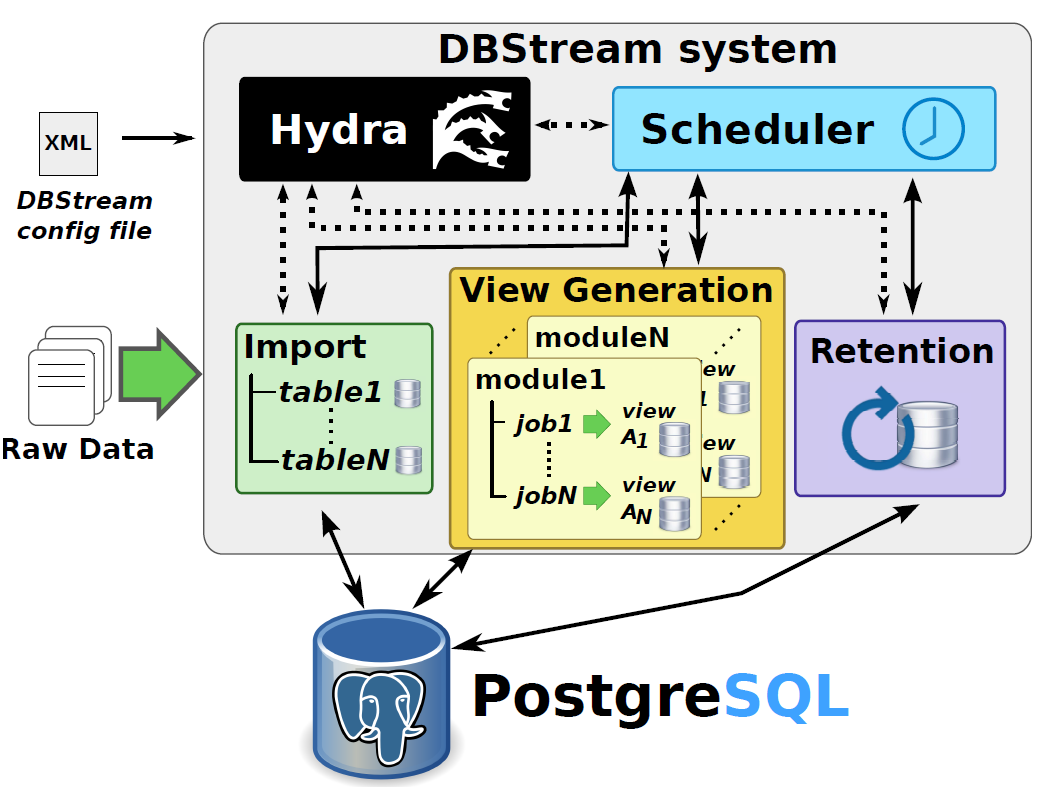
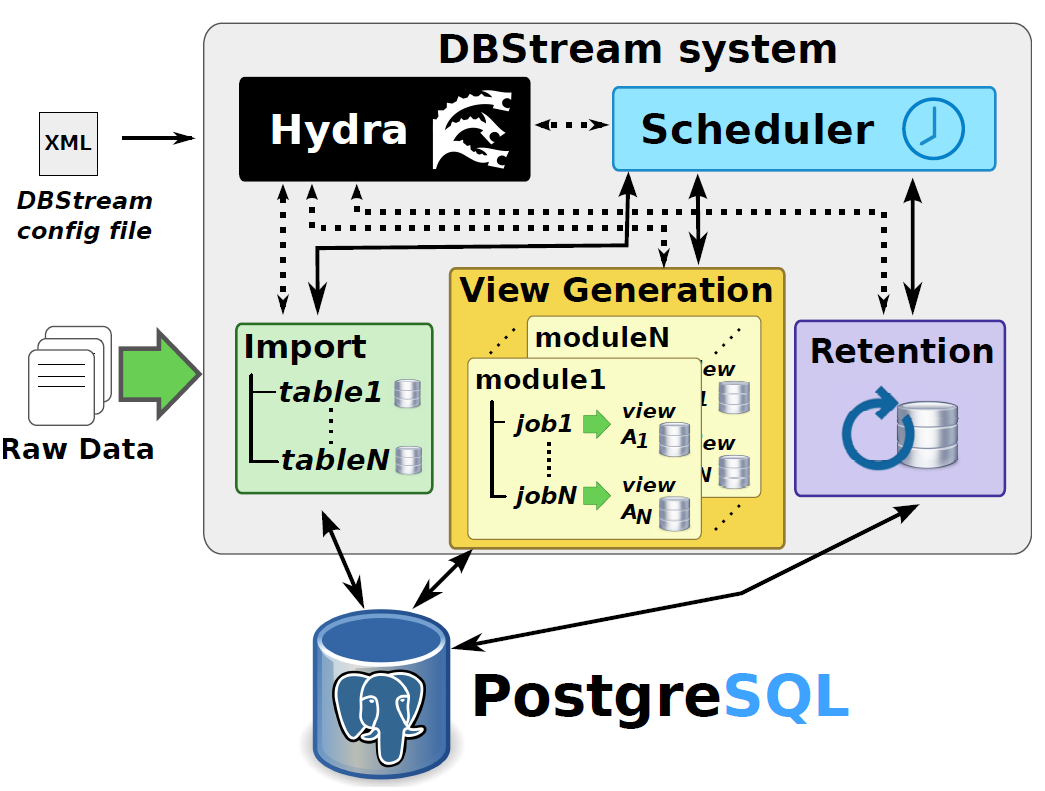
In DBStream, base tables store the raw data imported into the system, and materialized views (or views for short) store the results of queries such as aggregates and other analytics --- which may then be accessed by ad hoc queries and applications in the same way as base tables. Base tables and materialized views are stored in a time-partitioned format inside the PostgreSQL database, which we refer to as Continuous Tables (CT). Time partitioning makes it possible to insert new data without modifying the entire table; instead, only the newest partition is modified, leading to a significant performance increase.
A job defines how data are processed in DBStream, having one or more CTs as input, a single CT as output and an SQL query defining the processing task. An example job could be: "count the distinct destination IPs in the last 10 minutes". This job would be executed whenever 10 new minutes of data have been added to the input table (independently of the wall clock time) and stored in the corresponding CT.
DBStream consists of a set of modules running as separate operating system processes. The Scheduler defines the order in which jobs are executed, and besides avoiding resource contention, it ensures that data batches are processed in chronological order for any given table or view. Import modules may pre-process the raw data if necessary, and signal the availability of new data to the Scheduler. The scheduler then runs jobs that update the base tables with newly arrived data and create indices, followed by incrementally updating the materialized views. Each view update is done by running an SQL query that retrieves the previous state of the view and modifies it to account for newly arrived data; new results are then inserted into a new partition of the view, and indices are created for this partition. View Generation modules register jobs at the Scheduler.
Finally, the Retention module is responsible for implementing data retention policies. It monitors base tables and views, deleting old data based on predefined storage size quotas and other data retention policies. Since each base table and view is partitioned by time, deleting old data is simple: it suffices to drop the oldest partition(s).
The DBStream system is operated by an application server process called hydra, which reads the DBStream configuration file, starts all modules, and monitors them over time. Status information is fetched from those modules and made available in a centralized location. Modules can be placed on separate machines, and external programs can connect directly to DBStream modules by issuing simple HTTP requests.
Deployment Requirements and Execution
DBStream and the used libraries assume that you are using golang version 1.2.x (https://golang.org/). Therefore, for older versions of Ubuntu like e.g. 12.04 you might follow the instructions in this guide: http://www.tuomotanskanen.fi/installing-go-1-2-on-ubuntu-12-04-lts. Next we provide a step-by-step description on how to install and run DBStream, as well as how DBStream is integrated in mPlane.
Ia - Installing DBStream
DBStream source code uses the go language; to compile the go source code of DBStream you have to install the go language:
apt-get install golangDBStream also uses several open source libraries which you have to install in order to compile DBStream. First you need to create a directory where go code can be downloaded to, e.g.:
mkdir ~/goNext you need to export a new environment variable so go knows where to put the code, which at least in bash works like this:
export GOPATH=~/goNow you can install the needed libraries with the following command:
go get github.com/lxn/go-pgsql
go get github.com/go-martini/martini
go get code.google.com/p/vitess/go/cgzipNow go to the DBStream server directory e.g.:
cd ~/source/dbstream/and run the build script there:
./build.shThe resulting executables will be placed in the \texttt{bin/} directory. The main executable is called hydra which starts the application server.
cd bin/
./hydra --config ../config/serverConfig.xmlEdit the server configuration and add the modules of DBStream you want to use. If you want to get some information about the application server you can run the command remote to monitor and control the server. This command shows the current status of the application server every second:
watch -n 1 ./remoteThe default config also starts a CopyFile module. You can see that currently no files are being imported by checking:
http://localhost:3000/DBSImportThe next step before actually running DBStream is to set up Postgres as a DBStream backend. The first step is to install PostgreSQL. We where using versions from up to 8.4 for DBStream, but rather recommend to use newer versions, like e.g. 9.3. On ubuntu you can install PostgreSQL with the following command:
apt-get install postgresql-9.3Then you have to create an operating system and database user for DBStream. From now on, we will assume that this user is called dbs_test but you can choose any other user name, just make sure that all parts of the configuration are adapted as well. This user has to be a postgres superuser.
sudo useradd -s /bin/bash -m dbs_testNow you have to create a database with the name of that user; note that this database will also be used to store all data imported to and processed with DBStream.
sudo su - postgres # change to the postgres user
createuser -P -s dbs_test # create new user with superuser rights and set password
createdb dbs_test # create a database with the same name
exit # close the postgres user sessionDBStream uses a tablespaces to store data on disk, namely dbs_ts0. For testing purposes, we will locate them in the home folder of the dbs_test user, but in a real setup you probably want to set them to a large RAID-10 storage array.
sudo mkdir /home/dbs_test/dbs_ts0 # create data0
sudo chown postgres /home/dbs_test/dbs_ts0 # This directory must be accessible by the
postgres system user
Now the newly created DBStream database needs to be initialized. Therefore, change to the test directory and login into the database you just created:
cd test
psql dbs_test # Please note that you need to login with a database superuser,
so you might want to change to the dbs_test user first.If you log correctly into the database you should see something like this:
psql (9.3.6)
Type "help" for help.
dbs_test=# Now run the following command to initialize some DBStream internal tables.
\i initialize.sqlIf all steps from this part were successfully completed you can go on and start DBStream for the first time.
Ib - Installing DBStream from Vagrant
Within mPlane, and to ease the installation of a DBStream instance without the burden of installing and configuring all its components, we provide a DBStream-Vagrant based image at https://github.com/arbaer/dbstream/tree/master/vagrant. Vagrant is a tool for building complete development environments, aiming at lowering development environment setup time.
To run a DBStream instance using Vagrant, you need to follow these steps:
Install vagrant version 1.7.2 from http://www.vagrantup.com/downloads.html
Add the ubuntu/trusty64 box:
vagrant box add ubuntu/trusty64Start the virtual machine:
vagrant upConnect to the virtual machine:
vagrant sshIn case you want to recompile DBStream set the GOPATH environment variable and execute the build.sh single threaded:
export GOPATH=~/go
./build.sh single
II - Running DBStream
Now that DBStream is already installed, follow these steps to start it:
First we need to change to the test directory.
cd test # if you are comming here from vagrant, the directory is src/dbstream/testNow you should see the executables in this directory (e.g. hydra, math_probe, math_repo, scheduler and remote). For this example it is the best to open three shells. In the first shell we will run dbstream, in the second we will run the import source and the third will be used for monitoring DBStream.
In the monitoring shell run the following command:
cd dbstream/test
watch -n 1 ./remoteIn the dbstream shell execute the following command
cd dbstream/test
./hydra --config sc_tstat.xmlIn the import source shell run the following command:
cd dbstream/test
./math_probe --config math_probe.xml --repoUrl "localhost:3000" --startTime 2006-01-02T15:04:05If all went well, you should now be able to log into postgres, and check some preloaded tables:
psql dbstream
select * from example_log_tcp_complete;To cleanup the tables and run the example import again, inside postgres execute the following command:
select dbs_drop_table('example_log_tcp_complete');
select dbs_drop_table('tstat_test');and in the shell run:
rm -rf /tmp/target/
III - mPlane Integration
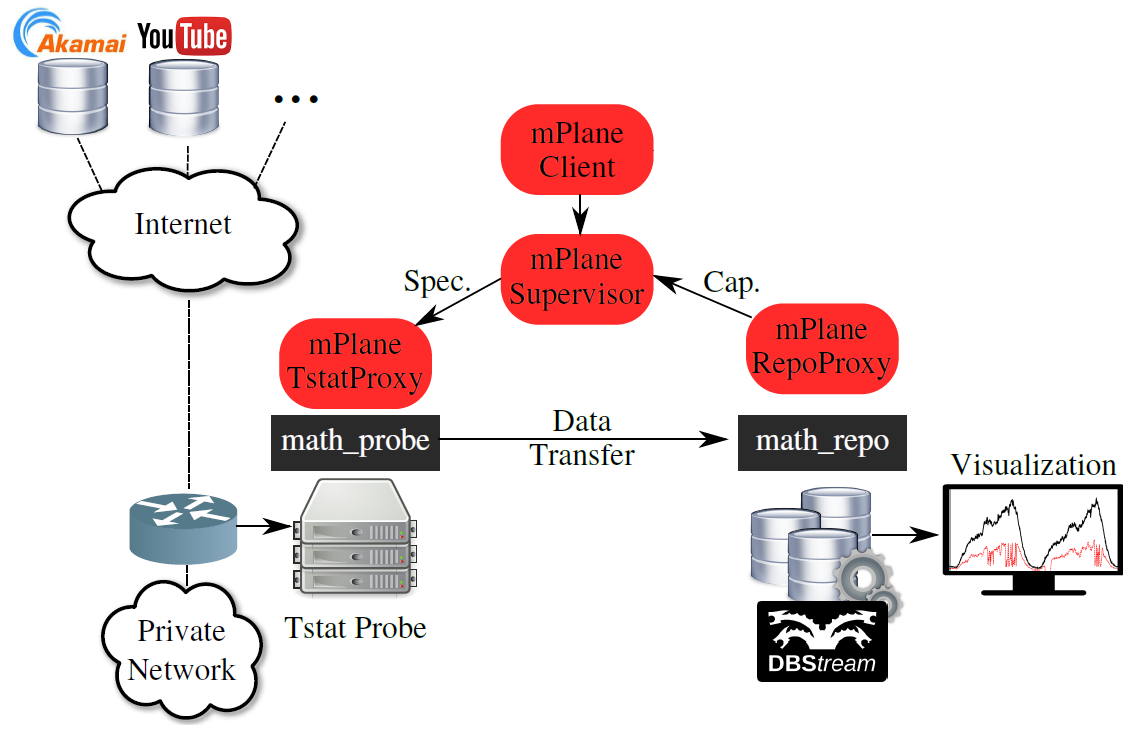
In mPlane, DBStream is integrated and used together with the Tstat probe, storing and analyzing the data captured and exported by the probe. The integration includes a mPlane proxy to the repository (RepoProxy) and a data transfer protocol which enables the Tstat probe to send bulk measurements to DBstream, and DBStream to import these measurements into tables for further analysis by the Analysis Modules it runs (e.g., anomaly detection). Data transfer is achieved through a customized protocol we have named MATH - Mplane Authorized Transfer via HTTP.
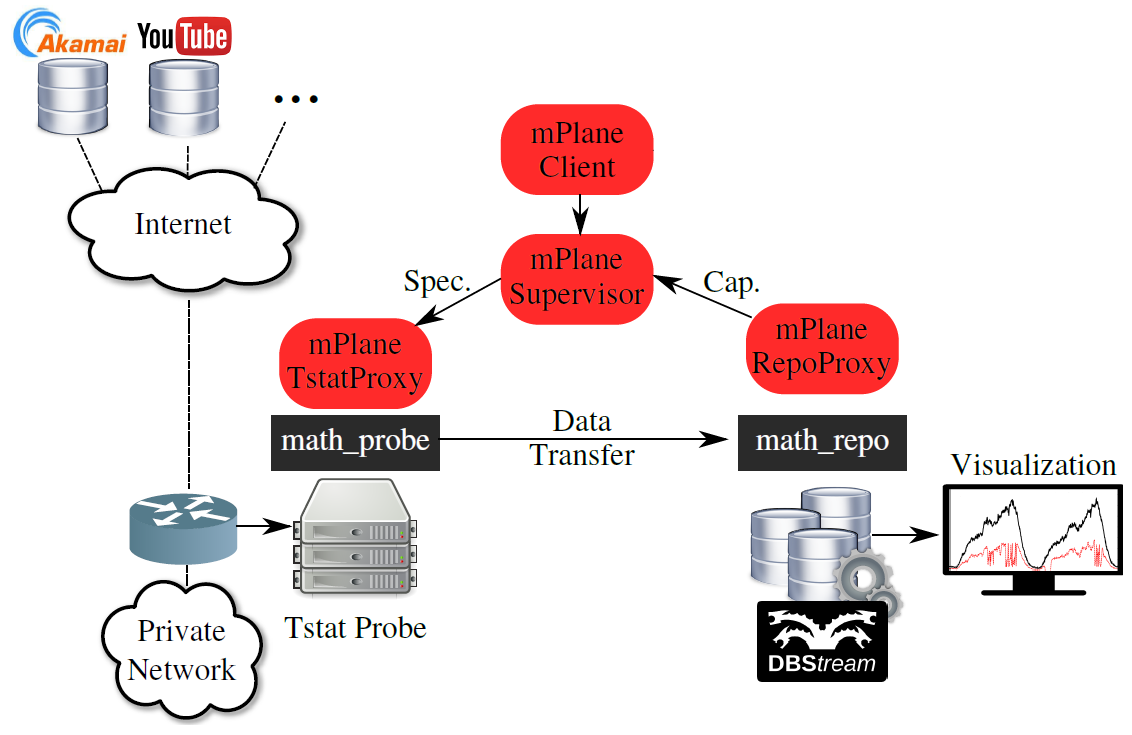
MATH is composed of two modules, math_probe and math_repo, the former runs together with the Tstat probe and it handles the transfer of Tstat logs to a mPlane repository, the latter runs together with DBStream and handles the importing of the received Tstat logs into the DBStream database. Both MATH modules come with XML configuration files which extends the flexibility of the MATH protocol to be used with other probes and repositories.
To run the mPlane integration of DBStream with Tstat, you have to follow the next steps:
Download and install the Tstat and DBStream tools, both available at GitHub under https://github.com/fp7mplane/components/tree/master/tstat and https://github.com/arbaer/dbstream, respectively.
Install the mPlane framework and probe and repository mPlane proxies
git clone https://github.com/fp7mplane/protocol-ri.gitEnter the protocol-ri/mplane folder and rename (or remove) components. Then, check out the one available on github.
cd protocol-ri/mplane/
mv components components.orig (or rm -rf components)
git clone https://github.com/fp7mplane/components/
cd ../Add the following required capabilities at the Supervisor configuration files conf/supervisor.conf:
tstat-log_http_complete = guest,admin
tstat-exporter_log = guest,admin
repository-collect_log = guest,adminRun the mPlane Supervisor:
./scripts/mpsup --config ./conf/supervisor.confRun the Tstat proxy:
./scripts/mpcom --config ./mplane/components/tstat/conf/tstat.confRun the Repository proxy:
./scripts/mpcom --config ./mplane/components/tstat/conf/tstatrepository.confRun the mPlane Client:
./scripts/mpcli --config ./conf/client.confRun both DBStream and the MATH importer module, math_repo:
./hydra --config sc_tstat.xml
./math_repoRun Tstat and the MATH exporter module, math_probe, using the mPlane Client shell:
|mplane| runcap tstat-log_tcp_complete-core
|when| = now + inf|mplane| runcap tstat-exporter_log
repository.url = localhost:3000At this point in time, the Tstat proxy sends log files collected by Tstat to the repository proxy, and the log files are then stored in DBStream, where different analysis modules perform further analysis.
New Features supported by the mPlane project
Thanks to the support of the mPlane project we extended DBStream functionalities with the following features:
- CEL Extension: we extended the functionality of the CEL language, making it much easier to code an analysis job on top of DBStream.
- MATH: we added MATH (Mplane Authorized Transfer via HTTP), a protocol to export bulk data in the form of logs from a mPlane probe (e.g., Tstat) and to import it into DBStream.
- Machine Learning @DBStream: we added Machine Learning analysis capabilities to DBStream, by integrating a well know Machine Learning toolbox (WEKA) directly into the data processing of DBStream jobs.
- Better Performance through Scheduling: we improved the performance of DBStream in terms of complete job completion time by studying and developing different job scheduling approaches.
References
All DBStream and DBStream-related (e.g., MATH) sources and binaries are accessible on GitHub at https://github.com/arbaer/dbstream.
Additional documentation on DBStream can be found at https://github.com/arbaer/dbstream/blob/master/README.md.
Further information about DBStream can be found in the following research papers:
[1] Arian Baer, Pedro Casas, Lukasz Golab and Alessandro Finamore "DBStream: An Online Aggregation, Filtering and Processing System for Network Traffic Monitoring" http://dx.doi.org/10.1109/IWCMC.2014.6906426 Wireless Communications and Mobile Computing Conference (IWCMC), 2014
[2] Arian Baer, Alessandro Finamore, Pedro Casas, Lukasz Golab, Marco Mellia "Large-Scale Network Traffic Monitoring with DBStream, a System for Rolling Big Data Analysis" http://www.tlc-networks.polito.it/mellia/papers/BigData14.pdf IEEE International Conference on Big Data (IEEE BigData), 2014
If you are using DBStream for any research purpose we would highly appreciate if you would reference [2].
DBStream is open source software and the full source code along with a detailed installation description are available under the AGPL license on github.com at: https://github.com/arbaer/dbstream.




{kind=link}
{kind=link}
|
The information available on this website is property of the contributing authors from the mPlane Consortium (project FP7-ICT-318627) and does not necessarily reflect the view of the European Commission. The information in this website is provided "as is", and no guarantee or warranty is given that the information is fit for any particular purpose. The user uses the information at its sole risk and liability. |