- ABOUT MPLANE
- NEWS
- Blogs
- EXTERNAL ADVISORY BOARD
- PUBLIC DELIVERABLES
- PUBLICATIONS
- TALKS
- STANDARDIZATION
- CALENDAR & EVENTS
- CONTACTS
- mPlane Industrial Workshop
- 1st PhD school on BigData
- EuCNC 2015 Exhibition
- Open Datasets
- SOFTWARE
- Reference Implementations and SDK
- Probes
- Repositories and Scheduling
- Reasoners and analysis modules
- Reasoner for Content Popularity Estimation
- Reasoner for the Content Curation use case
- RC1 reasoner
- WebQoE Reasoner
- Mobile RCA Reasoner
- mpAD_Reasoner: Anomaly Detection and Diagnosis
- SLA verification and troubleshooting
- GLIMPSE Traceroute Reasoner
- SEARUM
- LPR
- Middlebox Taxonomy
- IGP Weight Inference
- DisNETPerf
- ADTool
- Entropy-based Anomaly Detection Module
- Spark Jobs for processing raw data
- Webrowse modules
- iGreedy - Anycast Enumeration and Geolocation Module
- Other tools
- Demonstration guidelines
- Use cases
- mPlane Final Workshop
You are here
ADTool - Statistical Anomaly Detection
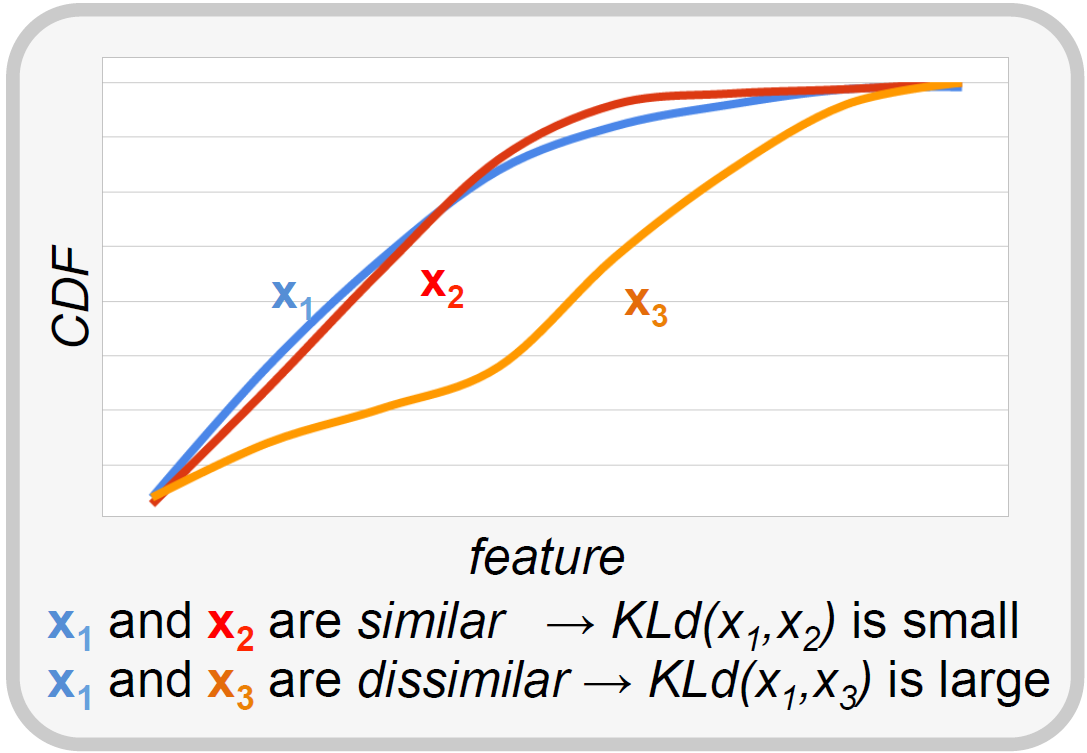
ADTool implements a Statistical-based Anomaly Detection Analysis Module running on top of the DBStream streaming data-warehouse system. The goal of ADTool is to detect macroscopic anomalies in the traffic served to a large number of users, meaning anomalies that involve multiple flows and/or affect multiple users at the same time. For this purpose, it resorts to the temporal analysis of the entire probability distributions of certain traffic descriptors or features.
The proposed statistical non-parametric anomaly detection algorithm works by comparing the current probability distribution of a traffic feature to a set of reference distributions describing its normal behavior. At each iteration, the algorithm determines a reference for normality by running a reference-set identification sub-routine. The purpose is to find distributions in the recent past (e.g., in an observation window of one or two weeks) which are best suited to represent the current one. In the testing phase the algorithm assesses the statistical compatibility of the current distribution against the distributions included in the reference set. If the current distribution is flagged as anomalous a warning is raised, and it is discharged to be considered as future reference of normality. The detection test checks if the average inter-distribution distance exceeds a certain anomaly upper bound. As for the distance metric between two distributions p and q, ADTool uses a symmetrized and normalized version of the well-known Kullback-Leibler (KL)-divergence:
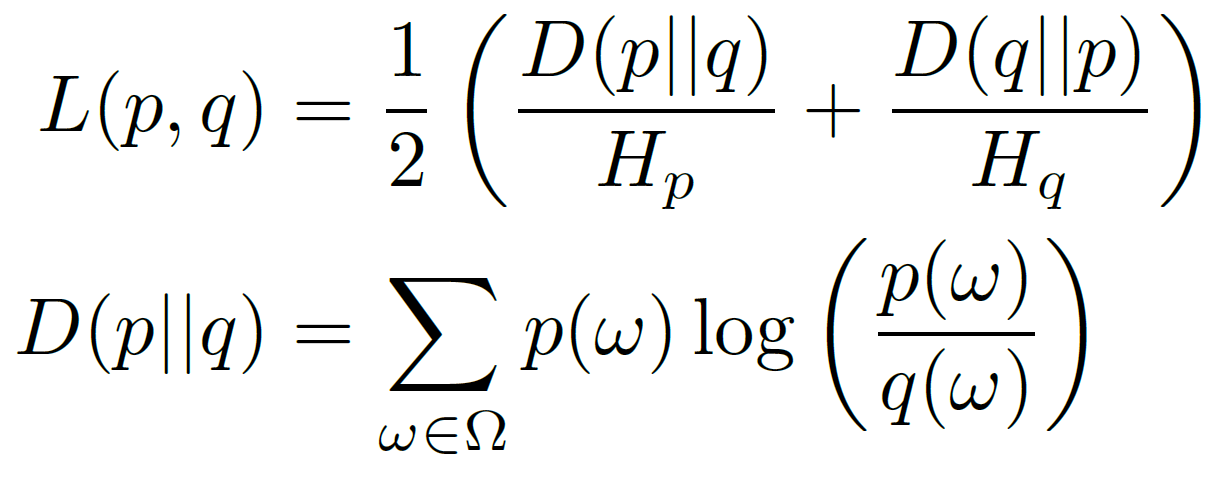
Features distribution are computed on a temporal basis considering time bins of fixed length, referred to as time scale. Time scale is a design parameter that can range from 1 to 60 minutes. Functionally speaking, the algorithm consists of two phases: the training and the detection phase. During the training phase the algorithm accumulates distribution time series for a period ranging between 7 and 14 days (depending on the considered timescale). Then, during the detection phase, it uses the information accumulated to identify a suitable reference for normality for the distribution under test. Results of the anomaly detection test, for each traffic dimension, and for each timescale, are logged independently.
For further details on ADTool, we refer the reader to deliverables D4.1 and D4.3, as well as the references therein.
Note that ADTool requires suitable DBStream jobs to compute traffic feature distributions with the required time-granularity. It is designed to run online, i.e. it processes the distributions of features as soon as they are available in the DBStream views.
List of Modules composing ADTool
ADTool consists of several modules which permit to define configuration parameters and set specific detection thresholds and conditions. The following is a list of these modules:
Configs.pm
This module provides an interface between the XML configuration file and the rest of the software. The parsing of the XML file is done by the \verb|XML::Simple| Perl standard module.
DataSrc.pm
This module provides an interface between the PostgreSQL database used by DBStream and the rest of the software. It allows to connect to the database, to query for the last available data to compute and write back the output. Both the read and the write interactions with the database are done by the standard Perl DBI module via SQL queries and inserts.
ENKLd.pm
This module provides the computation of the normalized Kullback-Leibler divergence between two distribution of values. The two distributions are passed to this module as array references and do not need to be normalized in advance.
RefSet.pm
This module defines the package RefSet for managing Reference Sets (collection of past distributions). After being instantiated, a "raw" RefSet object contains all the distributions in the specified reference window. The module provides functions to discard statistically-irrelevant distributions (e.g., not enough samples).
ADTest.pm
This module implements the testing logic of the CDN-AD algorithm. It requires the distribution to be tested, the reference set, and other algorithm parameters (i.e., $\alpha$, $\gamma$).
DBStream Jobs for ADTool
In order to run ADTool, it is necessary to set-up a suitable DBStream job to compute counters of the feature for each variable and time bin. The output view of the job should have the following columns:
serial_time
<variable name>
<feature name>
Note that a single view can be used to collect multiple features if the <variable_name> and the time resolution are compatible.
ADTool Module configuration
The configuration of the software is done via an XML file. The available options are:
[database] host
[database] port
[database] username
[database] password
[database] features table name (output of DBStream job)
[database] flags table name (output of ADTool)
[analysis] start timestamp
[analysis] end timestamp (0 means run forever)
[analysis] name of variable upon whom the job has computed the distribution
[analysis] feature name
[refset] width (in days)
[refset] guard period (in hours)
[refset] min refset size (minimum number of distributions in refset)
[refset] min distr size (minimum number of samples in distribution)
[refset] m (number of top ranked distributions in refset)
[refset] k (currently unused)
[ADtest] alpha (algorithm's sensitivity)
A sample configuration file looks like the following:
<ADTool_config>
<!-- *****************************************************************************************
task description
****************************************************************************************** -->
<Description>adtool on youtube (ip,imsi_cnt)</Description>
<!-- *****************************************************************************************
settings for database connection
****************************************************************************************** -->
<Database host="localhost" port="5440" dbname="dbstream" user="dbstream" password="FT4hhyhL" >
<features_table>adtool_mw14_gg11_youtube_features_serverip_600</features_table>
<flags_table>adtool_youtube_flags_serverip_600</flags_table>
</Database>
<!-- *****************************************************************************************
analysis settings (time span, granularity, feature name, etc.)
****************************************************************************************** -->
<Analysis>
<start>1396648800</start><!-- beginning of analysis -->
<end>0</end><!-- end of analysis, 0 means run online -->
<granularity>600</granularity><!-- time granularity in seconds -->
<variable>server_ip</variable><!-- variable of the distributions -->
<feature>imsi_cnt</feature><!-- name of the traffic feature -->
</Analysis>
<!-- *****************************************************************************************
settings for reference set
****************************************************************************************** -->
<RefSet>
<width>7</width><!-- reference set time window in days -->
<guard>2</guard><!-- guard period in hours -->
<min_distr_size>100</min_distr_size><!-- min number of samples in distributions -->
<min_refset_size>80</min_refset_size><!-- min number of distributions in refset -->
<slack_var>0.1</slack_var><!-- for comparing size of timebins -->
<m>50</m><!-- usually ~1/4 min_refset_size -->
<k>2</k><!-- number of clusters for pruning --> <!-- currently unused -->
</RefSet>
<!-- *****************************************************************************************
settings for AD test
****************************************************************************************** -->
<ADTest>
<alpha>0.05</alpha><!-- sensitivity -->
</ADTest>
</ADTool_config
ADTool workflow
The logic is defined in the main executable \verb|adtool.pl|. The arguments for running the program are:
--config <XML_CONFIG_FILE>
--log <LOG_FILE>
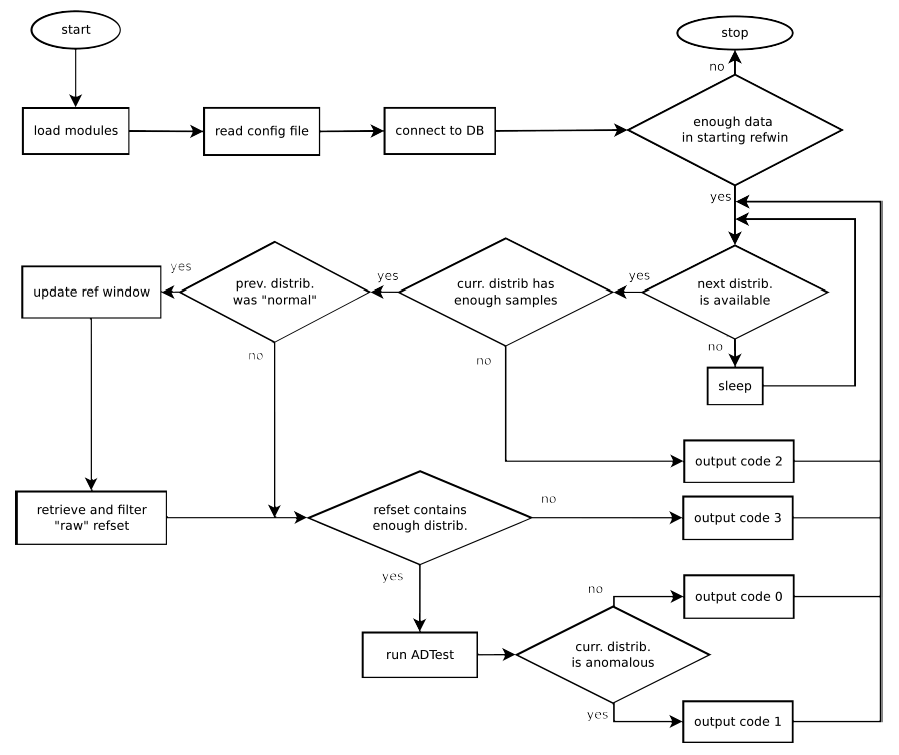
The execution workflow of AdTool is described in the Figure below:
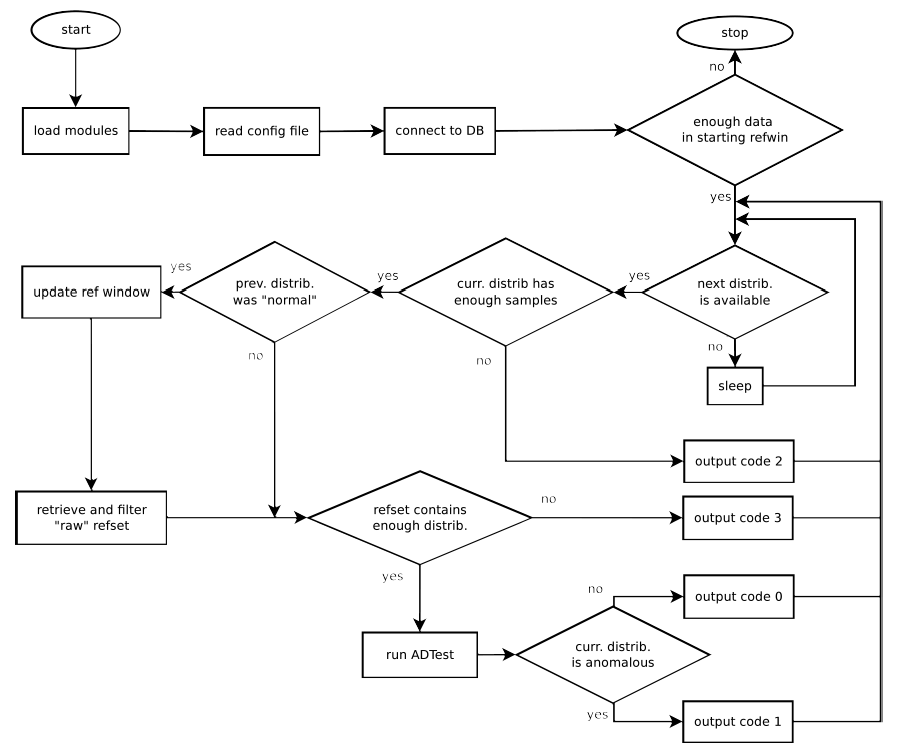
Upon completion of each iteration, the output is reported on STDOUT as well as on the database's flag table specified in the configuration. For each iteration running on a time-bin, the row inserted in the flag table is composed by the following column:
- beginning timestamp of the timebin
- feature name
- output code (0,1,2,3,4)
- score
- gamma
- Phi_{alpha}
- Output codes:
- 0: distribution is ``normal''
- 1: distribution is anomalous
- 2: distribution does not contain enough samples
- 3: refset does not contain enough distributions.
- 4: currently unused
ADTool code
--> version 1.0 (August 2014)
--> version 2.3 (August 2015, final release)






{kind=link}
{kind=link}
|
The information available on this website is property of the contributing authors from the mPlane Consortium (project FP7-ICT-318627) and does not necessarily reflect the view of the European Commission. The information in this website is provided "as is", and no guarantee or warranty is given that the information is fit for any particular purpose. The user uses the information at its sole risk and liability. |